The key in my opinion, to coding your first neural network is to sidestep the landmine that is using Tensorflow, and using nothing but Python, and numpy.
The code given below ‘learns’ that the output ‘y’ will be 0 if the input is an odd number in binary representation, and 1 if the input is an even number.
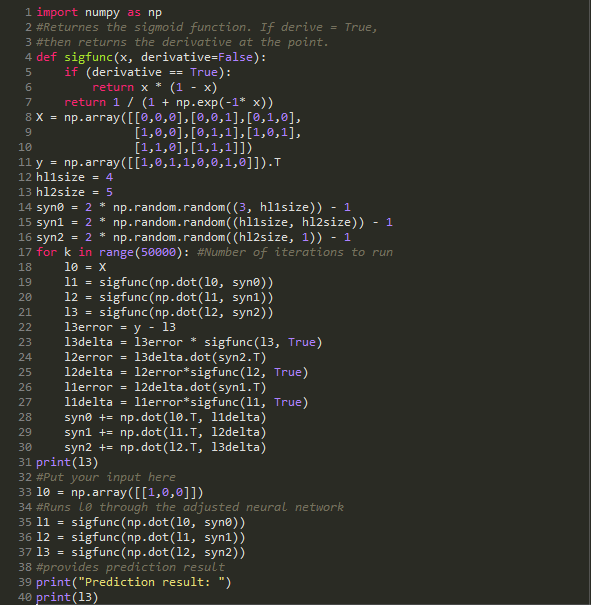
We begin the journey by understanding the sigmoid function:


This function is very widely used in neural networks. The purpose is to bring non-linearity into the model.
Another reason for this choice is that the derivative of the Sigmoid function:
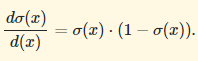
This means that one can easily create the following function:

This would return the derivative, as proven by eqn (1)
Weighing your errors
The derivative is useful because: whenever the neural network makes a ‘prediction’, it is important that the error in is adjusted correctly.

The concept of weighted error comes into play here. Penalizing what the neural network is less confident about heavily, and penalizing its most confident outputs the least. Which can be articulated in the following statement/code best:
Error = y – prediction
prediction_delta = Error*sigmoid_to_deriv(prediction)
The red boxes signify what might qualify as high confidence predictions. This implies that the multiplying the error with the derivative at that prediction leads to a small prediction_delta. Which implies lesser weightage to the error.
Synapses
It is extremely important that anyone attempting to code a neural network assimilates the concept of synapses.
Our first priority, after obviously the inputs is creating synapses. Synapses can be imagined to be weight matrices for the neural network. For purposes pertaining to the task ahead of us, we shall load random numbers into the matrix, which will act as weights initially, and we will update it with every iteration.
I hope everyone is familiar with matrix multiplication here. If not, I’ll give you the very basic, and a recommendation to look up some Khan Academy videos.

If we are to create a neural network with many hidden layers, this becomes essential.
After inspecting the code on top, as well as the picture below, you will have a perfect understanding of the process underlying neural networks.
Make sure you spend as much time as you need understanding this. Refer to the code simultaneously as well.
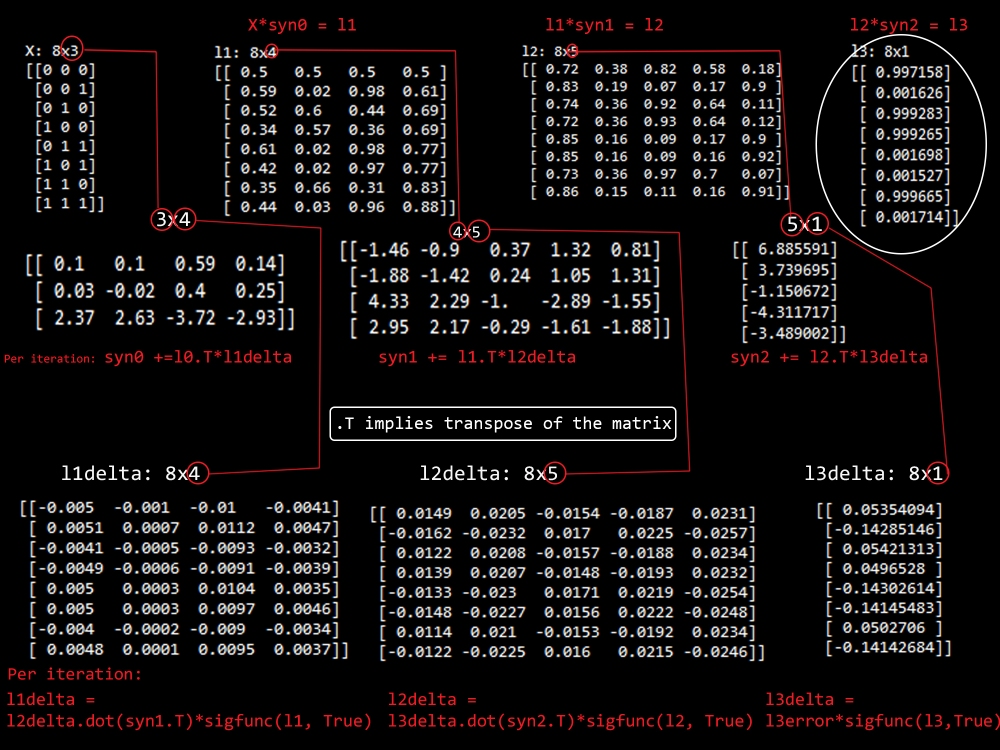
Backpropogation
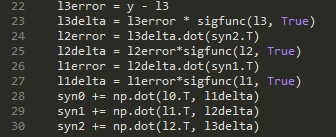
Looking at line 22 might make the concept of error obvious. However, can you guess what is happening on line 24?
What we do here is simply establish a metric of how each synapse in the network contributed to the overall error in each iteration.
For a concrete understanding of this concept, i’d suggest an exceptional source: Optimization: CS231n
Alphas &
Gradient Descent
Say I’m jumping around in a bowl shaped like a parabola. If the length i can jump is too long, and my purpose is to get to the lowest point, I might never get there, as i may keep overshooting the bottom. But say the bowl was not parabola shaped, but irregular with many local minimas, and say I jump extremely small distances, then the probability that I will get caught in a local minima for several iterations is extremely high.
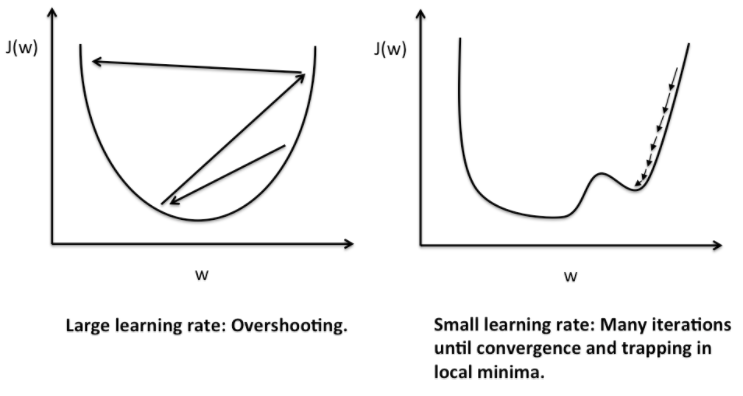
This impacts our ability to train in a massive manner.
So, an alpha parameter is introduced, which reduces the size of each ‘leap’. This is crucial to training speed, but also needs to be selected carefully.
This is just one of the several optimization techniques, among SGD, AdaGrad, ADAM, to name a few.

One thought on “Coding your first neural network from scratch”